An `epi_df` object, 129,638 x 5 with metadata:
* geo_type = state
* time_type = day
* as_of = 2021-12-01
# A tibble: 129,638 × 5
geo_value time_value version percent_cli case_rate_7d_av
* <chr> <date> <date> <dbl> <dbl>
1 ca 2020-06-01 2020-06-02 NA 6.63
2 ca 2020-06-01 2020-06-06 2.14 6.63
3 ca 2020-06-01 2020-06-07 2.14 6.63
4 ca 2020-06-01 2020-06-08 2.14 6.63
5 ca 2020-06-01 2020-06-09 2.11 6.63
6 ca 2020-06-01 2020-06-10 2.13 6.63
7 ca 2020-06-01 2020-06-11 2.20 6.63
8 ca 2020-06-01 2020-06-12 2.23 6.63
9 ca 2020-06-01 2020-06-13 2.22 6.63
10 ca 2020-06-01 2020-06-14 2.21 6.63
# ℹ 129,628 more rows
Mathematical modelling of disease / epidemics is very old
Daniel Bernoulli (1760) - studies inoculation against smallpox
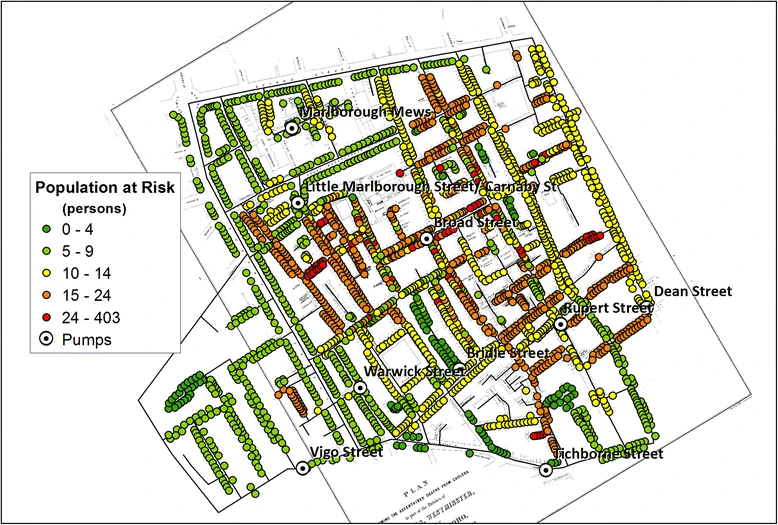
John Snow (1855) - cholera epidemic in London tied to a water pump
Ronald Ross (1902) - Nobel Prize in Medicine for work on malaria
Kermack and McKendrick (1927-1933) - basic epidemic (mathematical) model
Forecasting is also old, but not that old
US CDC Flu Challenge began in 2013
CDC’s Influenza Division has collaborated each flu season with external researchers on flu forecasting.
CDC has provided forecasting teams data, relevant public health forecasting targets, and forecast accuracy metrics while teams submit their forecasts, which are based on a variety of methods and data sources, each week.
The Covid-19 Pandemic
CDC pivoted their Flu Challenge to Covid-19 in June 2020
Similar efforts in Germany and then Europe
![]()
![]()
Nothing similar for Canada
CDC now has Flu and Covid simultaneously
Why the Forecast Hubs?
Collect public forecasts in a standard format and visualize
Used internally by CDC
Turns out, most individual teams’ forecasts are … not great
Combine submissions into an “Ensemble”

Some terminology

- As reported on 30 August 2023. Would look different as of 15 April 2023
- Counts for a Date are updated — “backfill” — as time passes
Revision triangle, Outpatient visits in WA 2022

Aside on Nowcasting
- When Epi’s say “nowcasting”, they typically mean “estimate the time-varying instantaneous reproduction number, \(R_t\)”

- My group built
{rtestim}doing for this nonparametrically - See also
{epinow2}and{epinowcast}for flexible (but slow) Bayesian methods based on compartmental models
Models used for COVID-19 hospitalizations

Comparison of real-time performance
- Deep learning isn’t worth it.
- Hospitalization due to Covid; all US states, weekly, from January 2021 to December 2022

Calculating growth rates

Outlier detection

Canned forecasters that work out of the box.
But, you can adjust a lot of options
Flatline forecaster (CDC Baseline)
For each location, predict \[\hat{y}_{j,\ t+h} = y_{j,\ t}\]
Prediction intervals are determined using the quantiles of the residuals

Canned forecasters that work out of the box.
But, you can adjust a lot of options
AR forecaster
Use an AR model with an extra feature, e.g.: \[\hat{y}_{j,\ t+h} = \mu + a_0 y_{j,\ t} + a_7 y_{j,\ t-7} + b_0 x_{j,\ t} + b_7 x_{j,\ t-7}\]
Here, all predictions (point forecast and intervals) use Quantile Regression

Visualize a result for 1 forecast date, 2 locations
Code
edf <- case_death_rate_subset
fd <- as.Date("2021-11-30")
geos <- c("wa", "ca")
h <- 1:28
tedf <- edf |> filter(time_value >= fd)
# use most recent 3 months for training
edf <- edf |> filter(time_value < fd, time_value >= fd - 90L)
rec <- epi_recipe(edf) |>
step_epi_lag(case_rate, lag = c(0, 7, 14, 21)) |>
step_epi_lag(death_rate, lag = c(0, 7, 14)) |>
step_epi_ahead(death_rate, ahead = h)
f <- frosting() |>
layer_predict() |>
layer_unnest(.pred) |>
layer_naomit(distn) |>
layer_add_forecast_date() |>
layer_threshold(distn)
ee <- smooth_quantile_reg(
quantile_levels = c(.05, .1, .25, .5, .75, .9, .95), outcome_locations = h
)
ewf <- epi_workflow(rec, ee, f)
the_fit <- ewf |> fit(edf)
latest <- get_test_data(rec, edf, fill_locf = TRUE) |>
filter(geo_value %in% geos)
preds <- predict(the_fit, new_data = latest) |>
mutate(forecast_date = fd, target_date = fd + ahead) |>
select(geo_value, target_date, .pred_distn = distn) |>
mutate(.pred = median(.pred_distn))
ggplot(preds) |>
plot_bands(preds, fill = tertiary) +
geom_vline(xintercept = ymd("2021-11-30"), linetype = "dashed") +
geom_line(
data = case_death_rate_subset |>
filter(time_value > ymd("2021-09-30"), geo_value %in% geos),
mapping = aes(x = time_value, y = death_rate)) +
geom_line(
mapping = aes(x = target_date, y = .pred), colour = primary,
linewidth = 1.5) +
facet_wrap(~geo_value) +
ylab("Covid deaths per 100K population") + xlab("Date") +
scale_y_continuous(expand = expansion(), limits = c(0, .75))
Community standard forecast format, FluSight Ensemble
- Choose a target signal, relevant to PH, incident hospitalizations
- Usually submit (every week), for weekly or daily horizons, up to a month out
- Point forecast and a set of quantiles
c(0.01, 0.025, 1:19 / 20, 0.975, 0.99) - Could produce categorical forecasts (“way up”, “up”, “steady”, “down”)
- Historically, could submit samples from a distribution

FluSight 2 week WIS

Overprediction and underprediction

Calibration

Comparing across disparate targets
- Target = (forecast date, horizon, location)
- Everything so far is “per target”
- Better (in my view), to normalize by “difficulty”
- Forecasters that do well when it’s “easy” aren’t adding anything

- Scale by baseline
- Aggregate with geometric mean
- A non-parametric space-time multiplier
- See https://doi.org/10.1073/pnas.2111453118
Forecast Hubs
Current
- The US CDC runs
- the FluSight Modelling Hub
- RSV Hub (just started)
- RespiCast - European CDC
- CDPH - West Nile Virus (coming in May)
- CFA runs Covid Hub (US)
- CFA starting an Rt Hub?
Past
- Scenario Modelling Hub (US) for Covid
- German Flu Hospitalization Hub
- European Covid Hub
- Germany + Poland Covid Hub
![]()
![]()

Target data?
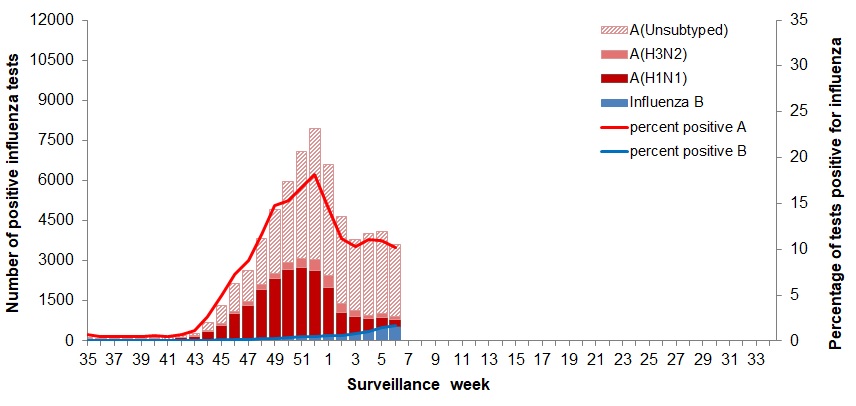
- Format is ick.
- We’ll try to make this available.
- And it’s history.
- Some is versioned
Thanks
- The CMU Delphi Team
- Centers for Disease Control and Prevention.
- Council of State and Territorial Epidemiologists
- NSERC
- Optum/United Healthcare, Change Healthcare.
- Google, Facebook, Amazon Web Services.
- Quidel, SafeGraph, Qualtrics.






