
Nonparametric estimation of time-varying reproduction numbers
Daniel J. McDonald

Mathematical modelling of disease / epidemics is very old
Daniel Bernoulli (1760) - studies inoculation against smallpox
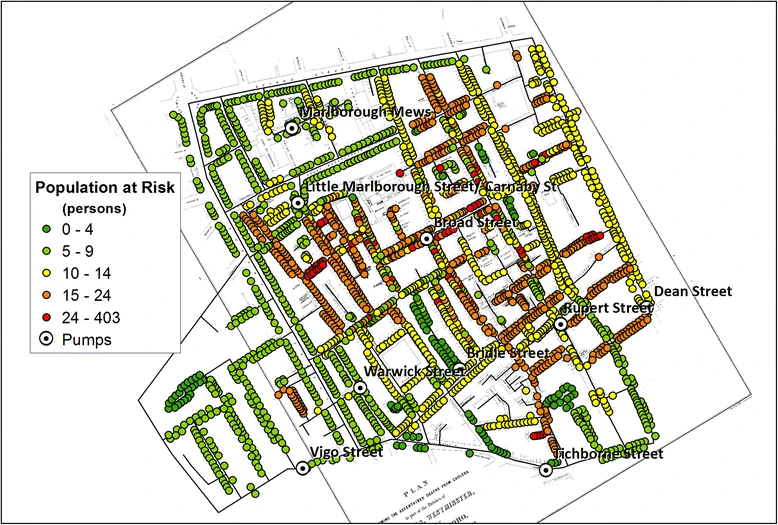
John Snow (1855) - cholera epidemic in London tied to a water pump
Ronald Ross (1902) - Nobel Prize in Medicine for work on malaria
Kermack and McKendrick (1927-1933) - basic epidemic (mathematical) model
\(R_0\) basic reproduction number
Dates at least to Alfred Lotka (1920s) and others (Feller, Blackwell, etc.)
The expected number of secondary infections due to a primary infection
- \(R_0 < 1\) ⟹ the epidemic will die out
- \(R_0 > 1\) ⟹ the epidemic will grow until everyone is infected

\(R_0\) is entirely retrospective
It’s a property of the pathogen in a fully susceptible (infinite) population
Each outbreak is like a new sample
To estimate something like this from data, the “bonehead” way is to
- Wait until the epidemic is over (no more infections circulating)
- Contact trace the primary infection responsible for each secondary infection
- Take a sample average of the number caused by each primary
- Possibly repeat over many outbreaks
30307-9/asset/daf522aa-ab16-4df8-ab69-212fb115a975/main.assets/gr4_lrg.jpg)
Of course no one actually does that
Lots of work on how to estimate \(R_0\)
The generation interval distribution \(g(a)\)

Stochastic SIR

Data issues
\(x_t\) is Infections, but we don’t ever see those
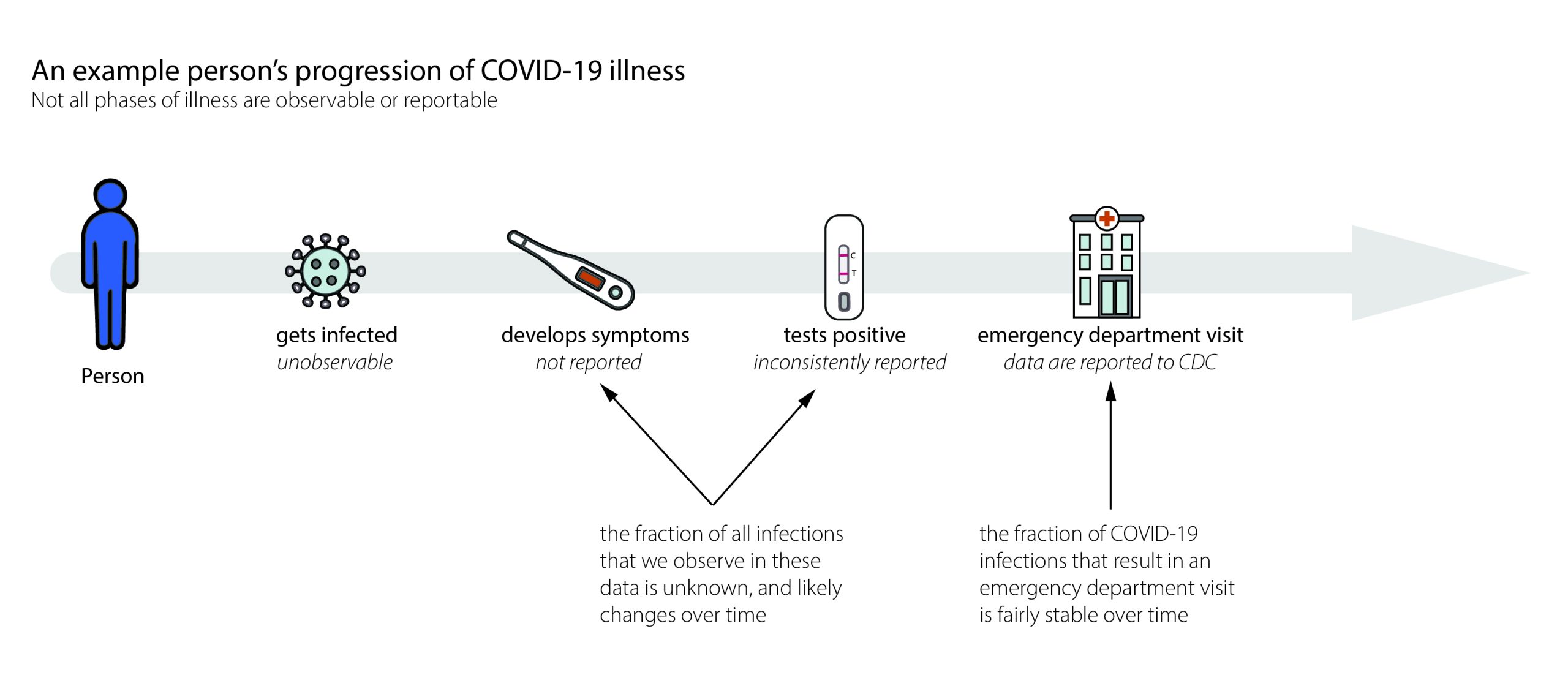
- Replace infections with cases
- Replace generation interval with serial interval
- Assume we have the serial interval
Serial interval distribution

Local adaptivity — \(\ell_1\) vs. \(\ell_2\)

Polynomial order, \(k=1\)
\[
\begin{aligned}
D^{(2)} &= \begin{bmatrix}
1 & -2 & 1 & & & \\
& 1 & -2 & 1 & & \\
& & & \ddots && \\
& & & 1 & -2 & 1
\end{bmatrix} \\ \\
&= D^{(1)}D^{(1)}\\ \\
&\in \mathbb{R}^{(n-k-1)\times n}
\end{aligned}
\]

Polynomial order, \(k=2\)
\[
\begin{aligned}
D^{(3)} &= \begin{bmatrix}
-1 & 3 & -3 & 1 & & \\
& -1 & 3 & -3 &1 & \\
& & & \ddots && \\
& & -1 & 3 & -3 & 1
\end{bmatrix} \\ \\
&= D^{(1)}D^{(2)}\\ \\
&\in \mathbb{R}^{(n-k-1)\times n}
\end{aligned}
\]

Canadian Covid-19 cases

\(R_t\) for Canadian Covid-19 cases

Reconvolved Canadian Covid-19 cases

Example simulations for different methods

{rtestim} software

Guts are in C++ for speed
Lots of the usual S3 methods
Approximate “confidence” bands
\(\widehat{R}\) is a member of a function space
Arbitrary spacing of observations
Built-in cross validation
Time-varying delay distributions
{rtestim} software
Guts are in C++ for speed
Lots of the usual S3 methods
Approximate “confidence” bands
\(\widehat{R}\) is a member of a function space
Arbitrary spacing of observations
Built-in cross validation
Time-varying delay distributions

Approximation + Delta method gives
\[ \textrm{Var}(\widehat{R}) = \left(\textrm{diag}(\widehat{y}) + \lambda D^{\mathsf{T}}D\right)^{\dagger} \left(\frac{1}{\eta^2}\right) \]
{rtestim} software
Guts are in C++ for speed
Lots of the usual S3 methods
Approximate “confidence” bands
\(\widehat{R}\) is a member of a function space
Arbitrary spacing of observations
Built-in cross validation
Time-varying delay distributions

The solution is an element of the space of discrete splines of order \(k\) (Tibshirani, 2020)
- Lets us interpolate (and extrapolate) to off-observation points
- Lets us handle uneven spacing
{rtestim} software
Guts are in C++ for speed
Lots of the usual S3 methods
Approximate “confidence” bands
\(\widehat{R}\) is a member of a function space
Arbitrary spacing of observations
Built-in cross validation
Time-varying delay distributions


{rtestim} software

Summary and collaborators
Contributions
- Framework for \(R_t\) estimation
- Naturally imposes smoothness
- Fast, extensible, easy to use
- Has “confidence” bands
Future work
- Allow Negative Binomial likelihood
- Deconvolve incidence
- Forecast
- Mixed smoothness behaviours
- Figure out CV for convolution
- Better confidence bands
- Use relationship with growth rate
Collaborators and funding



![]()
