flowchart LR
A("{epidatr}") --> C("{epiprocess}")
B("{epidatpy}") --> C
D("{covidcast}") --> C
C --> E("{epipredict}")
Sliding examples on epi_df
Correlations at different lags

Outlier detection and correction

Sliding examples on epi_df
Growth rates

Revision patterns
Example data object documentation, license, attribution
archive_cases_dv_subset package:epiprocess R Documentation
Subset of daily doctor visits and cases in archive format
Description:
This data source is based on information about outpatient visits,
provided to us by health system partners, and also contains
confirmed COVID-19 cases based on reports made available by the
Center for Systems Science and Engineering at Johns Hopkins
University. This example data ranges from June 1, 2020 to Dec 1,
2021, and is also limited to California, Florida, Texas, and New
York.
Usage:
archive_cases_dv_subset
Format:
An 'epi_archive' data format. The data table DT has 129,638 rows
and 5 columns:
geo_value the geographic value associated with each row of
measurements.
time_value the time value associated with each row of
measurements.
version the time value specifying the version for each row of
measurements.
percent_cli percentage of doctor’s visits with CLI (COVID-like
illness) computed from medical insurance claims
case_rate_7d_av 7-day average signal of number of new confirmed
deaths due to COVID-19 per 100,000 population, daily
Source:
This object contains a modified part of the COVID-19 Data
Repository by the Center for Systems Science and Engineering
(CSSE) at Johns Hopkins University as republished in the COVIDcast
Epidata API. This data set is licensed under the terms of the
Creative Commons Attribution 4.0 International license by Johns
Hopkins University on behalf of its Center for Systems Science in
Engineering. Copyright Johns Hopkins University 2020.
Modifications:
• From the COVIDcast Doctor Visits API: The signal
'percent_cli' is taken directly from the API without changes.
• From the COVIDcast Epidata API: 'case_rate_7d_av' signal was
computed by Delphi from the original JHU-CSSE data by
calculating moving averages of the preceding 7 days, so the
signal for June 7 is the average of the underlying data for
June 1 through 7, inclusive.
• Furthermore, the data is a subset of the full dataset, the
signal names slightly altered, and formatted into a tibble.

Latency investigation, > 2 days
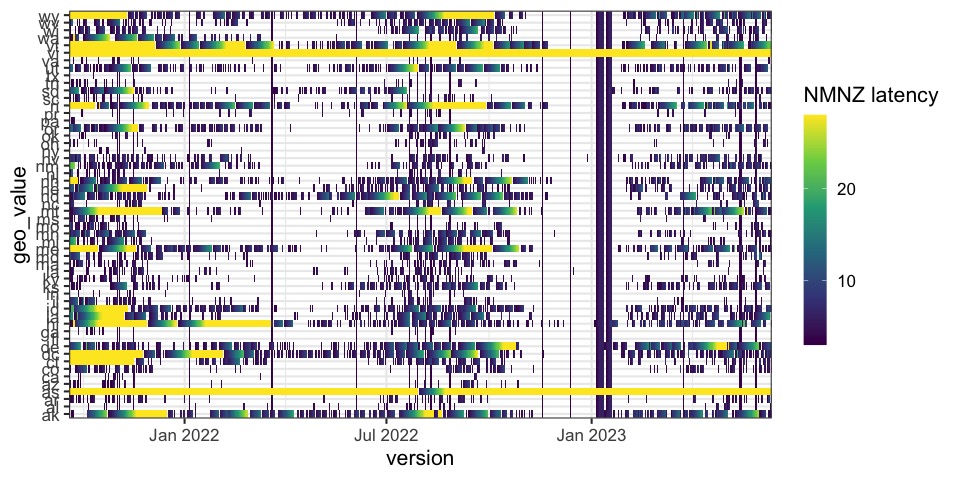
Visualize a result for 1 forecast date, 1 location
Code
fd <- as.Date("2021-11-30")
geos <- c("ut", "ca")
tedf <- edf %>% filter(time_value >= fd)
# use most recent 3 months for training
edf <- edf %>% filter(time_value < fd, time_value >= fd - 90L)
rec <- epi_recipe(edf) %>%
step_epi_lag(case_rate, lag = c(0, 7, 14, 21)) %>%
step_epi_lag(death_rate, lag = c(0, 7, 14)) %>%
step_epi_ahead(death_rate, ahead = 1:28)
f <- frosting() %>%
layer_predict() %>%
layer_unnest(.pred) %>%
layer_naomit(distn) %>%
layer_add_forecast_date() %>%
layer_threshold(distn)
ee <- smooth_quantile_reg(
tau = c(.1, .25, .5, .75, .9),
outcome_locations = 1:28,
degree = 3L
)
ewf <- epi_workflow(rec, ee, f)
the_fit <- ewf %>% fit(edf)
latest <- get_test_data(rec, edf, fill_locf = TRUE)
preds <- predict(the_fit, new_data = latest) %>%
mutate(forecast_date = fd, target_date = fd + ahead) %>%
select(geo_value, target_date, distn) %>%
pivot_quantiles(distn) %>%
filter(geo_value %in% geos)
ggplot(preds) +
geom_ribbon(aes(target_date, ymin = `0.1`, ymax = `0.9`),
fill = "cornflowerblue", alpha = .8) +
geom_ribbon(aes(target_date, ymin = `0.25`, ymax = `0.75`),
fill = "#00488E", alpha = .8) +
geom_line(data = bind_rows(tedf, edf) %>% filter(geo_value %in% geos),
aes(time_value, death_rate), size = 1.5) +
geom_line(aes(target_date, `0.5`), color = "orange", size = 1.5) +
geom_vline(xintercept = fd) +
facet_wrap(~geo_value) +
theme_bw(16) +
scale_x_date(name = "", date_labels = "%b %Y") +
ylab("Deaths per 100K inhabitants")
Questions?
